
Blog
Żużel Obstawianie Zakłady Bukmacherskie Na Żuże
Żużel Obstawianie Zakłady Bukmacherskie Na Żużel
Oferta Sts Zakłady Na Dzisiaj I Jutro, Wyniki, Statystyki
Content
- Żużel Zakłady Bukmacherskie Jak Obstawiać Żużel?
- Jak Obstawiać Żużel?
- Dariusz Śledź, Trener Sparty Wrocław Po Meczu W Le
- Czytajogromne Bonusy I Zakłady Sportowe: Dowiedz Się Więcej O 888starz
- Drużynowo Bądź Indywidualnie?
- Takim Składem Zdemolowali Falubaz To Samo Zrobią Ze Spartą?
- Sport Żużlowy Bądź Da Się Usankcjonować Kontuzje? Piotr Rusiecki Jest Za Kasowaniem Punktów
- Żużel – [na Żywo] Puchar Ekstraligi W Gorzowie! Wicemistrz Świata W Obsadzie
- Sześć Spotkań Metalkas 2 Ekstraligi W Jeden Weekend Break!
- Sponsorzy Serwisu
- Obstawianie Zwycięzcy Meczu Lub Zawodów
- Porady Bukmacherskie
- Obstawianie Żużla To Nie Tylko Gotowe Kupony Ako
- Żużel Em Świecie
- Obstawianie Żużla – Popularne Zakłady
- Oferta Sts Na Sobotę I Niedzielę, Czyli Weekend Pełen Wrażeń
- Ekspert Grzmi Na Temat Zawodnika Stali “nie Można Po Trupach! “
- I I Ii Liga
- Gdzie Oglądać Żużel?
- Skrytykował Zawodnika Stali, A Sam Mhh Torze Był Chamem!
- Jak W Prl-u Finansowano Kluby Dzięki Niemu Żużel Był Masowy
- Żużel Zakłady Bukmacherskie – Lvbet
- Żużel Zakłady Bukmacherskie Sezonowe
- Zakłady Bukmacherskie Żużel – Gdzie Obstawiać?
- Ranga Zawodów
- Najlepszy Bukmacher Na Obstawianie Żużla
- Jakie Zakłady Bukmacherskie Na Żużel?
- Miniżużel Dlaczego Warto Move Uprawiać? (wideo)”
- Żużel Zakłady Bukmacherskie: Porady I Strategie
Jeśli potrzebujesz pomocy, są specjalne centra i actually infolinie. W przypadku, gdy masz trudności, nie wahaj się zastosować środków takich jak Alert Czasowy, Ograniczenie Strat, the nawet Samowykluczenie. Wartości punktowe w zakładach bukmacherskich opisane są w postaci ułamków dziesiętnych (np. over/under 2, 5). Dzięki temu, granice tych zakładów są wyj?tkowo wyraźnie oddzielone z siebie, bo przecież nie da się zdobyć pół bramki czy pół punktu. Przed nami kolejny tydzień żużlowych emocji, a co za tym idzie telewizyjnych transmisji. Sprawdź, gdzie będzie można oglądać mecze PGE Ekstraligi, Metalkas 2.
- Prognozy pogody warto uwzględnić podczas obstawiania żużla.
- W jakim celu stosuje się zakłady bukmacherskie żużel z . handicapem?
- Tor przygotowany, gospodarze dobrze spasowani po całym tygodniu treningów.
- W przypadku żużla, ten rodzaj zakładu bukmacherskiego dotyczyć będzie zwykle liczby punktów zdobytych przez wskazaną drużynę.
- Zakłady bukmacherskie można postawić w Superbet, Betclic, Fortuna, STS lub Betfan.
Obstawianie żużla jest um tyle specyficznym zajęciem, że jest to be able to sport jednocześnie indywidualny, jak i drużynowy. Wiele zależy zatem od tego, em jakie zmagania znajdziemy zakłady bukmacherskie. Na koniec chcemy odnotować to, co STS powinien poprawić. Przede wszystkim czekamy mhh pojawienie się promocji na żużel oraz możliwości budowania swoich własnych zakładów.
Żużel Zakłady Bukmacherskie Jak Obstawiać Żużel?
“Taki rodzaj zakładów bukmacherskich dostępny jest t przypadku zawodów drużynowych, do jakich zalicza się PGE Ekstraliga. Zakłady możesz postawić na zwycięstwo danej drużyny wraz z odjęciem jej z końcowego wyniku określonej liczby punktów. Weźmy pod lupę wspomniany już mecz Unii Leszno ze Stalą Gorzów. Możesz wysłać zakłady, że Unia wygra nawet, jeśli odejmie się jej 5. 5 punktu. Wówczas, żeby zakład został rozliczony veoma trafiony, leszczynianie muszą pokonać gorzowian company najmniej 6 punktami mostbet casino.
Ta cieszyła się jednak coraz mniejszym zainteresowaniem i wreszcie praktycznie zanikła. Można powiedzieć, że to wtedy zakończyła się romantyczna epoka czarnego sportu w naszym kraju. Obstawianie żużla ma swoje niewątpliwe atuty, ale też słabsze strony. O tym, na co warto zwrócić uwagę w tym zakresie warto wspomnieć.
Jak Obstawiać Żużel?
Następnie, trzeba wpłacić depozyt mhh konto gracza, by móc obstawiać za realne pieniądze, the także odebrać added bonus powitalny. Znajdź zakładkę z typami em żużel w ofercie bukmachera i kliknij w kurs interesującego Cię zakładu bukmacherskiego. Dobierz stawkę na swoim kuponie, zagraj zakład, a mhh koniec zaczekaj em rozstrzygnięcie wydarzeń. Świetna oferta na polskie ligi i turnieje indywidualne wzbogacona jest o zakłady live, które w STS funkcjonują bez zarzutu. Bukmacher bardzo szybko rozlicza zakłady, watts trakcie zawodów wystawia rynki na zwycięzcę każdego biegu, H2H w wyścigach lub na bieżąco aktualizuje handicapy.
25 czerwca rozpoczniemy rywalizację w Mistrzostwach Europy Par 250cc. Praktycznie przesądzone jest już, że Krono-Plast Włókniarz Częstochowa po sezonie 2024 będzie mniej duński, niż obecnie. Z trzech seniorów z Kraju Hamleta może zostać najwyżej dwóch, a może się tak też zdarzyć, że nie będzie żadnego.”
Dariusz Śledź, Trener Sparty Wrocław Po Meczu W Le
Ważnym aspektem jest także szybko” “działająca i niezacinająca się aplikacja, która jest jedną z lepszych na rynku. Bukmacherzy na żużel oferują też coraz częściej zakłady specjalne. Rozumie się przez nie coś wychodzącego poza szablony.
Nawet czerwona by jednak nie zaszkodziła w żaden sposób miejscowej drużynie. Podczas zaległego meczu PGE Ekstraligi pomiędzy Ebut. pl Stalą Gorzów, a Fogo Unią Leszno doszło do fatalnego w skutkach zdarzenia. Oskar Fajfer bez pardonu wjechał watts Andrzeja Lebiediewa i actually posłał Łotysza mhh tor. Lider Unii Leszno kontuzjowany opuścił nawierzchnię w karetce, natomiast zawodnik Stali został ukarany żółtą kartką. — Atak piką jest bardzo niebezpieczny — grzmiał ekspert po spotkaniu mostbet app.
Czytajogromne Bonusy I Zakłady Sportowe: Dowiedz Się Więcej O 888starz
Ponadto bardzo szybko dostępną mamy także pełną ofertę. Dzięki temu możemy śledzić zmiany w kursach i zmontować nasz kupon tak szybko jak tylko chcemy. W przypadku obstawiania żużla cierpliwość jest wskazana. Czasem wytypowany przez nas zawodnik lub drużyna słabo radzi sobie em początku zawodów, a new gracze myślą u zamykaniu kuponów bądź też kontrowaniu. Warunki atmosferyczne w tej dyscyplinie często rozdają karty. Mogą wpływać zarówno na przedwczesne przerwanie meczu, jego przełożenie na inny termin, czy też po prostu zmienić” “układ sił.
Łącznie to od kilkunastu do kilkudziesięciu kursów na poszczególne zawody, które możemy obstawiać w Superbecie w przypadku tej dyscypliny sportu. Co zatem LVBET powinien poprawić, aby doszlusować do forBET i actually STS? Na pewno zwiększyć zakres turniejów, które można typować.
Drużynowo Bądź Indywidualnie?
Pierwszym z polecanych bukmacherów z ofertą na żużel jest STS. U bukmachera znajdziemy zakłady na wszystkie czołowe żużlowe zmagania. W STS szeroką gamę typów spotkamy przede wszystkim przy okazji Speedway Grand Prix, light beer obstawiać można też mecze ligowe z . Polski i zagranicy. Podobnie jak watts przypadku wielu innych dyscyplin sportu, tidak i na żużel zakłady sezonowe są dostępne.
Przykładowo w meczu Unia Leszno – Stal Gorzów możesz wysłać zakłady, że wygrają gospodarze z Leszna. Które polskie zakłady bukmacherskie na żużel oferują najlepsze warunki gry? Przygotowaliśmy dla Ciebie spis TOP 3 serwisów bukmacherskich, gdzie warto rozpocząć obstawianie żużla online. Obstawiać tu możesz zakłady bukmacherskie em żużel w ligach krajowych i zagranicznych, a także Grand Prix.
Takim Składem Zdemolowali Falubaz To Samo Zrobią Ze Spartą?
Sporą “cegiełkę” do ngakl katastrofalnych wyników dołożył Bartosz Smektała. Były indywidualny mistrz świata juniorów punktuje ze średnią ledwie 1, 212 pkt/bieg i w” “Lesznie poważnie muszą rozważyć odesłanie go em trybuny. W sobotę prawdopodobnie w końcu będą mogli to zrobić.
- Warto pamiętać, że nawet podczas rywalizacji drużyn znajdziemy w ofercie zakłady na wyniki punktowe poszczególnych zawodników czy pojedynki H2H.
- Może się jednak także zmienić jego potencjalny rywal i utrudnić zdobycie punkty.
- Przykładowo w meczu Unia Leszno – Stal Gorzów możesz wysłać zakłady, że wygrają gospodarze z Leszna.
- Łącznie to z kilkunastu do kilkudziesięciu kursów na poszczególne zawody, które możemy obstawiać w Superbecie w przypadku tej dyscypliny sportu.
W rywalizacji um mistrzostwo Polski brało udział tylko dziesięć klubów, które finansowane były de facto przez państwo. 2024 Lubsport – wiadomości sportowe, wyniki i relacje live. Niedzielny mecz ebut. pl Stali Gorzów i Fogo Unii Leszno miał być kolejnym meczem bez większej historii.
Sport Żużlowy Bądź Da Się Usankcjonować Kontuzje? Piotr Rusiecki Jest Za Kasowaniem Punktów
Zapraszamy em relację z Drużynowego Pucharu Ekstraligi closed circuit, który odbył się na minitorze w Lublinie. Zakłady bukmacherskie nieodłącznie związane są z ryzykiem. Jeżeli zauważyłeś u siebie objawy uzależnienia skontaktuj się z serwisami oferującymi” “pomoc w wyjściu z nałogu hazardowego. Najwięcej żużlowych transmisji znajdziesz w Canal+Sport. W artykule znajdziesz najważniejsze zalety tej trójki. Dzięki temu, że transfery między klubami były mocno ograniczone trzeba było inwestować w młodzież, a new żeby „łapać” talenty trzeba było gwarantować im sprzęt.
- Podobnie jak opisani wyżej operatorzy udostępnia on nawet kilkadziesiąt kursów na poszczególne zawody.
- W odróżnieniu od większości bukmacherów na rodzimym rynku, ETOTO oferuje również zakłady na niższe ligi.
- Zapraszamy mhh relację z Drużynowego Pucharu Ekstraligi closed circuit, który odbył się na minitorze t Lublinie.
Ja nie skreślam jeszcze Unii Leszno — mówi były reprezentant Polski, Jan Krzystyniak. Przykro jest oglądać tak spektakularny upadek trzykrotnego indywidualnego mistrza świata. Tai Woffinden ma dopiero thirty-three lata, ale w niczym już nie und nimmer przypomina zawodnika, który jeszcze w 2018 r. Nie pomogła ani zmiana tunera, ani wyrzucenie mechaników. W Malilli podczas turnieju o indywidualne mistrzostwo świata było widać, że trouble jest w nim. Motocyklom nie brakowało szybkości, ale sam zawodnik, nie próbował jechać ofensywnie, the w kluczowych momentach po prostu przymykał gaz.
Żużel – [na Żywo] Puchar Ekstraligi W Gorzowie! Wicemistrz Świata W Obsadzie
Kluby, zmuszone do samodzielnego zapewniania sprzętu zawodnikom, szukały źródeł jego finansowania. A ponieważ działalność prywatna była dość ograniczona, opierano się na zakładach patronackich. Oczywiście przykłady można byłoby mnożyć, ponieważ nie und nimmer było klubu, który nie czerpałby pomocy z dużego zakładu znajdującego się watts okolicy. Osobnym rozdziałem były kluby z . Gdańska czy Bydgoszczy, opierające swoje funkcjonowanie na działalności resortów milicyjnych. Z czasem ujednolicono regulaminy i actually równolegle z oficjalnymi zawodami przeprowadzano rywalizację na motocyklach przygotowanych.
- Stworzyliśmy także eksperckie porady, dzięki którym będziecie wygrywać kupony na żużel.
- Selekcja rynków em rodzime i zagraniczne rozgrywki prezentuje się całkiem dobrze.
- Jednak po ataku Oskara Fajfera carry out szpitala trafił Andrzej Lebiediew i konstruera sytuacja wzbudza sporo kontrowersji.
- Zakłady na Large Prix w STS także stoją na najwyższym poziomie.
- I podobnie emocjonujące jest obstawianie meczy, ale grunzochse czytać na żużel kursy bukmacherskie?
Ten user przygotował przede wszystkim ofertę na najważniejsze imprezy z żużlowego kalendarza, na czele z SGP we polską Ekstraligą. W niektórych przypadkach możesz rozwinąć uzależnienie we nie zdawać sobie z tego sprawy. Wygrana jest miła, ale zawsze ważne jest, aby pamiętać, że zakłady keineswegs są przeznaczone mhh zarobek. Korzystaj z zasobów edukacyjnych we dowiedz się więcej, zanim postawisz swój pierwszy zakład. We wtorek 18 czerwca zakończymy pierwszą część sezonu rozgrywek U24 Ekstraligi. Fogo Unia Leszno jest em ostatnim miejscu t ligowej tabeli!
Sześć Spotkań Metalkas 2 Ekstraligi W Jeden End Of The Week!
Karambol Oskara Fajfera i Andrzeja Lebiediewa w zaległym meczu PGE Ekstraligi pomiędzy Ebut. pl Stalą Gorzów a Fogo Unią Leszno jest odmieniany przez wszystkie przypadki. Postawę zawodnika z Gorzowa mocno skrytykował były reprezentant Polski, Jan Krzystyniak. Jak się okazuje, 66-latek również mum na koncie pewien “wybryk”, którego pamiętać raczej nie chce. Poniżej, w ramach podsumowania prezentujemy wszystkie najważniejsze informacje dotyczące obstawiania żużla. W meczach ligowych trener ustawia zawodnika pod jednym z numerów startowych (seniorzy numery 1-5 oraz” “9-14, juniorzy 6, seven oraz 14, 12-15, zawodnicy u24 7, 16).
Typ under 39, a few działa wówczas w drugą stronę, gdyż gracz typuje zgromadzoną przez drużynę liczbę punktów poniżej wskazanej wartości (39 punktów i mniej). Warto podkreślić, że zakłady over/under w żużlu pojawiają się t ofercie bukmacherów najczęściej dopiero w” “dzień meczu. Warto też podkreślić, że dostępne są zakłady H2H na zawodników, którzy nie rywalizują se sobą w tym samym meczu. Wśród plusów możemy wskazać także promocje bukmacherskie, które czasem pojawiają się w ofercie bukmacherów na obstawianie żużla. Bonusy tego rodzaju jak zakład bez ryzyka czy też wyższe kursy względnie gra bez podatku.
Sponsorzy Serwisu
NovyHotel Falubaz Zielona Góra jest pozytywnym zaskoczeniem PGE Ekstraligi. Zielonogórzanie mają szansę być pierwszym od trzech bekv?m beniaminkiem, który utrzyma się w elicie. Na razie zajmują szóste, a więc trzecie miejsce od końca.
- Możesz postawić chociażby, że Emil Sajfutdinow zdobędzie więcej punktów, niż Bartosz Zmarzlik.
- Choć jego drużyna z Oxford przegrała, to reprezentant Polski ma powody perform uśmiechu.
- Bukmacher prezentuje w tej dyscyplinie tak samo wysoki poziom, company forBET i niezależnie od tego lub wybierzesz forBET lub STS, będziesz w pełni zadowolony.
- Ten owner przygotował przede wszystkim ofertę na najważniejsze imprezy z żużlowego kalendarza, na czele z SGP i actually polską Ekstraligą.
- Gracze, których interesuje obstawianie żużla mogą znaleźć różnorodną ofertę typów na zawody i mecze w tej dyscyplinie sportu.
Niektórzy zawodnicy na dane zawody przyjeżdżają z niezbyt poważnym nastawieniem. Czasem zatem typowanie dobrego rezultatu w wykonaniu potencjalnych faworytów nie jest najlepszą opcją. Zawody Grand Prix odbywają się na “domowym” torze jednego unces zawodników, to będzie miał on spore szanse na osiągnięcie dobrego wyniku. Kolejny z polecanych bukmacherów z ofertą em żużel to ETOTO. Podobnie jak opisani wyżej operatorzy udostępnia on nawet kilkadziesiąt kursów na poszczególne zawody.
Obstawianie Zwycięzcy Meczu Lub Zawodów
Fan wszelakich dyscyplin z żużla przez siatkówkę aż do piłki nożnej. Przed pracą dla portalu legalnibukmacherzy. pl zbierał doświadczenie m. in. W Przeglądzie Sportowym oraz komentował mecze koszykówki. W poradniku znajdziesz 3 porady rozpisane mhh zakłady live, przedmeczowe oraz cykl Large Prix. Przechodzimy teraz do trzech” “kluczowych porad, które wpłyną na wyższą skuteczność waszych zakładów em żużel. Jedna porada dotyczy zakładów reside, kolejna zakładów pre-match, an ostatnia typowania Grand Prix.
- Oczywiście przykłady można byłoby mnożyć, ponieważ nie und nimmer było klubu, który nie czerpałby pomocy z dużego zakładu znajdującego się watts okolicy.
- Poniżej, w ramach podsumowania prezentujemy wszystkie najważniejsze informacje dotyczące obstawiania żużla.
- Zakłady bukmacherskie żużel nie ograniczają Cię wyłącznie do obstawiania zwycięzcy meczu.
- Jak pokazuje grafika z danymi, największy handicap em większości torów PGE Ekstraligi w ubiegłym sezonie dawały skrajne pola A i D.
- Można powiedzieć, że to wtedy zakończyła się romantyczna epoka czarnego sportu w naszym kraju.
- Z trzech seniorów z Kraju Hamleta może zostać najwyżej dwóch, a new może się tidak też zdarzyć, że nie będzie żadnego.”
Janusz Kołodziej od kilku tygodni leczy kontuzję ramienia, której doznał podczas meczu ZOOLeszcz GKM-u Grudziądz z Fogo Unią Leszno. Od tamtej pory Kołodziej na treningu pojawił się kilka razy, ale sam przyznał, że była to be able to pochopna decyzja. Fantastyczny występ Macieja Janowskiego w Kings Lynn. Choć jego drużyna z Oxford przegrała, to reprezentant Polski ma powody perform uśmiechu. Kapitan Betard Sparty przegrał tylko dwa razy we na swoim koncie dopisał aż 16 punktów. Texom Stal Rzeszów w tym roku zasłynęła z . kilku kreatywnych działań pionu marketingowego.
Porady Bukmacherskie
Dokładnie jak obstawiać żużel opisaliśmy wewnątrz tekstu. Bukmacherzy na żużel już przedstawieni, a zatem przejdźmy do zasad obstawiania tego jakże pięknego we emocjonującego sportu. Zakłady bukmacherskie można postawić w Superbet, Betclic, Fortuna, STS albo Betfan. Poniżej zapoznasz się z bonusami na żużel, przygotowanymi przez tych operatorów. Mając chociaż podstawową wiedzą z zakresu specyfiki speedwaya, typowanie zawodów jest ciekawą alternatywą dla bardziej popularnych u bukmacherów konkurencji. Warto pamiętać, że ranga zawodów jest w tym przypadku istotna.
- Marża na cykl Speedway Grand Tarifs zbliża się do poziomu 4%, podczas gdy zakłady w rodzimych rozgrywkach przekraczają poziom 8%.
- Warto pamiętać, że ranga zawodów jest w tym przypadku istotna.
- Średnia marża na mecze zagraniczne mieści się t przedziale 3, 50-4, 50%.
Ligę duńską, szwedzką, angielską oraz indywidualne turnieje w tych krajach. Zakłady na Great Prix w STS także stoją mhh najwyższym poziomie. Operator jako jedyny daje możliwość typowania umiej?tno?ci do Grand Prix (można obstawiać zwycięzcę kwalifikacji i H2H). Plusem są także unikatowe zakłady długoterminowe na występy Polaków w cyklu Great Prix.
Obstawianie Żużla To Nie Tylko Gotowe Kupony Ako
I podobnie emocjonujące jest obstawianie meczy, ale yak czytać na żużel kursy bukmacherskie? Zakłady wystawiają kursy t formacie dziesiętnym, corp oznacza, że łatwo możesz policzyć potencjalną wygraną. Kurs 1 ) 90 oznacza, że stawiając 10 złotych możesz zarobić blisko 17 złotych. Pomnóż kurs przez stawkę i odejmij z wyniku 12% podatku bukmacherskiego. Kursy na żużel można czytać też jako wskazówkę, którą drużynę czy zawodnika bukmacher wskazuje jako faworyta. Im niższy kurs, tym zdaniem bukmacherów większe prawdopodobieństwo na zaistnienie danego zdarzenia np.
- Czasem zatem typowanie dobrego rezultatu w wykonaniu potencjalnych faworytów nie jest najlepszą opcją.
- Obstawianie żużla jest przeznaczone raczej do miłośników tego sportu, którzy wiedzą gdzie i kiedy warto szukać zakładów.
- Potem podeprzeć się statystykami pól startowych i actually wybrać te, które powinny dać największe szanse na zwycięstwo.
- Gospodarze mieli spokojnie pokonać trapioną kontuzjami Unię i tidak też się stało.
Oznaczają, który z nich zdobędzie więcej punktów watts danym meczu. Najczęściej, jeśli chodzi um PGE Ekstraligę, to w zakładach tych uwzględnia się wyłącznie zasadniczą fazę meczu bez biegów nominowanych. Możesz postawić chociażby, że Emil Sajfutdinow zdobędzie więcej punktów, niż Bartosz Zmarzlik. Zakłady bukmacherskie żużel nie ograniczają Cię wyłącznie do obstawiania zwycięzcy meczu. Chodzi tutaj o wytypowanie czy dana drużyna bądź zawodnik (do wyboru) zdobędą więcej punktów, niż zakłada bukmacher.
Żużel Na Świecie
I odwrotnie, internet marketing wyższe kursy, tym zdaniem bukmachera mniejsze szanse, że in order to się wydarzy np. Zakłady na żużel dostępne u legalnych bukmacherów w Polsce. Zawody obstawiać możemy przede wszystkim w ramach oferty przedmeczowej i na żywo.
- Na terytorium Polski zakłady wzajemne mogą oferować jedynie te podmioty, które posiadają zezwolenie mhh urządzanie zakładów wzajemnych.
- Jasno pokazuje in order to, że jeśli” “obstawiasz na żywo zwycięzcę biegu, to powinieneś skupić się na żużlowcach startujących unces pól A oraz D.
- Polecane zakłady bukmacherskie na żużel znajdziesz w naszym materiale.
Na przykład możesz wytypować, że Stal Gorzów watts najbliższym meczu zdobędzie powyżej 46. a few punktu lub, że Bartosz Zmarzlik przywiezie więcej niż 12. 5 punktu. W ramach cyklu SGP typować możemy rozstrzygnięcia przy poszczególnych zawodach, a także zakłady specjalne. To łącznie kilkadziesiąt kursów na każdą z” “edycji żużlowego Grand Tarifs.
Blog
Poggi felicitó a los diputados electos y los convocó a “trabajar juntos por una provincia y un país mejor”

El gobernador Claudio Poggi publicó un mensaje en sus redes sociales luego de que se conocieran los resultados del escrutinio provisorio que confirmaron la victoria de La Libertad Avanza en San Luis con el 51,52% de los votos. El Frente Justicialista de Alberto Rodríguez Saá quedó en segundo lugar con el 33,37%.
“Como gobernador de la provincia de San Luis felicito a Mónica Becerra, Carlos Almena y Jorge Fernández, diputados nacionales que resultaron electos para representar a todos los sanluiseños”, escribió.
Al mismo tiempo, les deseó “muchos éxitos en la labor legislativa que desempeñarán a partir del próximo 10 de diciembre”.
El mandatario provincial también convocó a los nuevos representantes a trabajar de manera conjunta: “Los invito a que trabajemos juntos para construir entre todos una provincia y un país mejor”.
Con el 98,42% de las mesas escrutadas, en San Luis La Libertad Avanza cosechó 132.027 votos, mientras que el justicialismo 85.576.

El gobernador Claudio Poggi tuvo una audiencia este viernes, en Casa de Gobierno, con el vicegobernador y presidente de la Cámara de Senadores, Ricardo Endeiza, el presidente de la Cámara de Diputados, Alberto Leyes, y los presidentes de los bloques oficialistas de las cámaras de Diputados y Senadores, Eugenia Gallardo y Martín Olivero, respectivamente. Dialogaron sobre la reforma judicial que impulsa Poggi a través de diversos proyectos de ley. Tras intercambiar opiniones con distintos sectores, se ha propuesto una modificación en el proyecto de ley de la eliminación de la feria judicial, para que esta sea de 15 días en enero y una semana en julio.
“Son cuestiones que obviamente han de tratar ambas cámaras de la Legislatura provincial, pero es lo que conversamos después de haber escuchado a los distintos actores, ya que no todos tienen la misma visión”, explicó Endeiza al finalizar el encuentro. Consideró que se trata de un “acto de reflexión, de humildad institucional, un acto republicano de decir ‘nos hemos escuchado’. Entendemos que si quizá no todos queden contentos, pero intentamos buscar el término medio”.
“Si bien formamos parte de distintos poderes, formamos un equipo. Evidentemente en nuestro espacio, que integra el oficialismo provincial, tenemos una actividad legislativa coordinada y somos quienes representamos, llevamos adelante e impulsamos las iniciativas que el Poder Ejecutivo presenta. En este sentido tuvimos una reunión con el Gobernador para analizar el devenir de la finalización del año legislativo 2025”, refirió Endeiza.

Como es habitual en la jornada posterior a cada elección, se realizarán tareas de limpieza y organización en las escuelas de San Luis que participarán del proceso electoral, con el objetivo de garantizar que los establecimientos estén en condiciones óptimas para el normal desarrollo de las clases.
Esta medida, prevista dentro de los protocolos establecidos para el uso de instituciones educativas durante procesos electorales, permite garantizar el cuidado de los espacios y el adecuado desarrollo de las actividades escolares.
Listado de instituciones afectadas a la votación:
- ZOILO CONCHA-ESC.N°51 SEGUNDO MENDOZA
- CNEL.M.CARREAS-ESC.N°51 SEGUNDO MENDOZA
- R.B.JURADO-ESC.N°51 SEGUNDO MENDOZA
- N°9 A.P.A.D.I.S
- Nº7 BURBUJITAS
- EDU.N° 28 RENE FAVALORO
- N°11 DR C.J.RODRÍGUEZ
- R.GUIRALDES-ESC.N°77 MAESTROS PUNTANOS
- GAB.MISTRAL-ESC.N°77 MAESTROS PUNTANOS
- TEC.N°4 FRAY LUIS BELTRÁN
- CARPINTERÍA-ESC.N°7 CONSTANCIO C.VIGIL
- R.B.DÍAZ-ESC.N°7 CONSTANCIO C.VIGIL
- N°98 GOB.JOSÉ SANTOS ORTIZ
- TEC.N°7 DR.MANUEL SADOSKY
- N°314 PROV.DE LA RIOJA
- NORTE-INST.DE FORMACION DOC.CONT.
- SUR-INST.DE FORMACION DOC.CONT.
- N°9 DR.ESTEBAN ADARO
- TEC.N°10 MARTÍN M.GUEMES
- N°7 GRAL.M.BELGRANO
- N°184 M.BELGRANO
- N°12 DR.R.CARRILLO
- N°1 DRA.CAROLINA TOBAR GARCIA
- N°36 BERNARDO A.HOUSSAY
- N°432 C.DEL PEREGRINO I PRIM
- N°35 C.DEL PEREGRINO II SEC
- LOS EUCALIPTUS-ESC.N°2 PUERTAS DEL SOL
- LOS CASTAÑOS-ESC.N°2 PUERTAS DEL SOL
- LOS CEREZOS-ESC.N°2 PUERTAS DEL SOL
- TEC.N°5 ALVAREZ CONDARCO
- 49 GOB. LINDOR QUIROGA
- GEN.GEPU
- NOGOLI-ESC.N°2 NICOLÁS A.DE SAN LUIS
- PJE LAS ARTES-ESC.N°2 NICOLÁS A.DE SAN LUIS
- N°70 PROV.DE SAN LUIS
- DON BOSCO
- N°175 GRAL.SAN MARTÍN
- EDU.N°1 J.PASCUAL PRINGLES
- N°427 PROV.DE CORDOBA
- SAN LUIS REY DE FRANCIA
- N°8 SARGENTO BAIGORRIA
- N°66 MONSEÑOR TIBILETTI
- N°5 B.MITRE
- N°3 MANUEL BELGRANO
- EDU.N°2 P.D.BAZAN
- N°313 ROSARIO M.SIMÓN
- N°2 BERNARDINO RIVADAVIA
- N°172 MISIONES
- N°27 S.CAMARERO
- N°27 S.CAMARERO
- EDU.N°3 EVA PERÓN
- EDU.N°3 EVA PERÓN
- EDU.N°3 EVA PERÓN
- N°6 STA.MARIA EUFRASIA
- GENERATIVA RUKA
- N°16 MARIA DELIA GATICA
- N°17 POLO GODOY ROJO
- N°38 MARIE CURIE
- N°24 PANCHA HERNÁNDEZ
- TEC.N°9 D.F.SARMIENTO
- EDU.N°21 PUERTA DE CUYO
- EDU.N°21 PUERTA DE CUYO
- N°4 JUAN TULIO ZABALA
- N°446 PUEBLO PUNTANO DE LA INDEPENDENCIA
- N°13 PROF.R.MOYANO
- N°13 PROF.R.MOYANO
- TEC.N°37 ING.G.AVE LALLEMANT
- N°264 JUAN MARTÍN DE P
- N°139 B.MITRE
- N°23 U.RODRÍGUEZ SAÁ
- N°1 ROSENDA QUIROGA
- N°40 HÉROES DE MALVINAS
- N°434 NUEVOS DESAFÍOS
- NELSON MANDELA
- N°14 MARTÍN L.KING SECUNDARIO
- N°13 ESTHER DEL R.GUEVARA
- EDU.N°6 CABO PRINCIPAL FABRICIO ALCARAZ
- N°267 GOB.E.MENDOZA
- N°22 BERNARDO O’HIGGINS
- N°323 JUAN W.GEZ
- N°141 LOS ANDES
- N°17 L.JOFRE Y MENESES
- N°10 JUAN E.VACCA
- N°311 LUIS JOFRE
- GEN DESAGUADERO SAN LUIS
- N°436 JUAN JOSÉ PASO
- EDU.N°16 TUCUMAN
- N°337 INDEP.ARGENTINA
- N°13 ANT.ARGENTINA
- HOGAR N°22 GOB.L.LANDABURU
- N°142 GOB.S.BESSO
- N°441 CAP.DE F.P.E.GIACHINO
- N°113 J.A.ORTIZ ESTRADA
- EDU.N°22 URBANO J.NUÑEZ
- N°357 MÁXIMO CAMARGO
- TEC.N°28 J.M.DE PUEYRREDON
- N°3 MANUEL BELGRANO
- N°114 DR.R.GUTIERREZ
- N°11 GDRO.J.R.AGUIRRE
- ESC.N°217 MARIA R.DE ASTUDILLO
- N°204 MTRO.N.VILLEGAS
- N°201 DANIEL VILLEGAS
- N°202 GOB.G.MENDOZA
- N°146 GDRO.T.CUELLO
- EDU.N°5 SEN.A.BERTIN
- N°179 EJ.ARGENTINO
- N°381 SOLDADO PUNTANO
- N°2 ESTANCIA GRANDE-PRIMARIO
- N°2 ESTANCIA GRANDE-SECUNDARIO
- N°328 H.P.DEL ARA.G.BELGRANO
- NTRA.SEÑORA DEL CARMEN
- N°10 M.E.V.LUCERO-PRIMARIA
- DIG BILINGÜE M.GANDHI
- N°10 M.E.V.LUCERO-SECUNDARIA
- N° 14 MIN. SUP. T DE JUSTICIA DR. LUCO
- N°176 MTRA.N.E.PEREZ DE FERRER
- N°7 E.GALEANO
- TEC.N°20 ANTONIO BERNI
- TEC.N°19 BERNARDINO RIVADAVIA
- N°106 PROF.T.FERRARI
- TEC.N°15 ING.A.MERCAU
- N°187 JOSÉ HERNÁNDEZ
- N°18 NICOLASA BERRONDO
- N°18 NICOLASA BERRONDO
- N°40 RICARDO ROJAS
- N° 147 PROV. DE MENDOZA
- N°240 PROV.DE CORRIENTES
- N°33 VICENTE DUPUY
- N°29 R.DE ESC.DE S.MARTÍN
- EDU.N°9 DR.J.LLERENA
- N°31 MARIANO MORENO
- N°32 JUSTO DARACT
- N°11 B.JUÁREZ
- N°388 SGTO.E.ROMERO
- N°43 DR.TOMAS JOFRE
- N°152 ALAS ARGENTINAS
- N°371 JUAN B.ALBERDI
- EDU.N°20 JUAN W.GEZ
- N°6 DR.L.R.BARROSO
- N°69 MTRA.O.E.SARDEN
- EPA N° 8 LEONARDO DA VINCI
- EDU.N°10 R.PODETTI
- N°431 NELY CHENAU DE VECINO
- N°151 PROV.DE T.DEL FUEGO
- N°324 F.MUÑOZ DE FOURCADE
- N°200 CAP.FAUSTO GAVAZZI
- N°37 J.B.ALBERDI
- N°429 GREGORIO AGÜERO
- TEC.N°16 JESUS OBRERO
- EDU.N°11 S.CORTINEZ
- N°272 CAPITAL FEDERAL
- N°82 GRAL LAS HERAS
- TEC.N°21 MARIA AUXILIADORA
- N° 242 PABLO PIZZURNO
- N°452-DR.V.LUCO
- N°38 GRAL.P.LUCERO
- N°210 GRAL.PEDERNERA
- N°270 A.DEL C.BAZÁN
- N°271 CAUTIVAS PUNTANAS
- TEC.N°17 V.BRIGADA AÉREA
- N°411 C.V.A.DE SAN JUAN
- N°251 SANTIAGO DEL ESTERO
- N°417 F.NAVARRO
- N°73 LOS TRES GRANADEROS
- N°76 L.Quiroga De Lucero
- N°74 B.RODRÍGUEZ JURADO
- Nº27 DR.ELEODORO LOBOS
- N°250 TOMÁS ESPORA
- EDU.N°18 C.ROSALES
- N°285 GDRO.D.ORTIZ
- N°285 GDRO.D.ORTIZ
- N°104 D.F.SARMIENTO
- N°215 MNTRO.A.M.GARRO
- N°178 J.I.PEDERNERA
- N°213 MAESTROS SANLUISEÑOS
- N°362 GDRO.M.PEREZ
- N°249 C.GARCIA TORRES
- N°442 A.RODRÍGUEZ SAÁ
- N°156 GDRO.JOSÉ G.BUSTOS
- EDU.N°17 H.IRIGOYEN
- N°398 JUSTO DARACT
- N°395 GDRO.V.CONCHA
- N°158 JOSÉ M.ESTRADA
- ESCUELA N° 437 JUAN CRISÓSTOMO LAFINUR
- N°220 H.DE AYOHUMA
- N°219 A.DEL C.G.VELEZ
- N°295 M.E.S.DE AMODEY
- INDEPENDENCIA-EPA.N°9 DR.H.DE LA MOTTA
- J.AZURDUY-EPA.Nº9 DR.H.DE LA MOTTA
- N°435 PUEBLO COMECHINGON
- N°181 SAN JOSÉ DE CALASANZ
- N°288 ANTONIO E.AGÜERO
- EDU.N°27 GDOR.S.BESSO
- EDU.N°26 M.P.DE BECERRA
- N°221 I.ROMERO DE PACHECO
- N°159 PROV.DE JUJUY
- N°237 M.T.CHIRINO
- N°223 GDRO.J.M.PRINGLES
- N°48 F.BERRONDO
- EDU.N°19 SARMIENTO
- N°296 PROF.C.CARLETTI
- N°298 MTRO.E.DARACT
- N°171 PINTOR B.M.MUÑOZ
- N°290 DIR.TEÓFILO GATICA
- N°259 VICEDIR.J.T.LUCERO
- TEC.N°30 FRAGATA SARMIENTO
- TEC N° 31 PROFESOR VÍCTOR SAÁ
- N°50 EULALIO ASTUDILLO
- N°95 VÍCTOR MERCANTE
- N°199 PROV.DE BUENOS AIRES
- N°196 MTRA.M.M.DE RAMIREZ
- N°236 VICEDIR.J.BELZUNCE
- N°61 S.R.DOMINGO MATHEU
- N°198 P.FEDERAL ARGENTINA
- N°292 DIP.R.PÁEZ MONTERO
- N°84 DALMIRO S.ADARO
- N°224 MTRO.V.GUIÑAZÚ
- N°308 NICOLÁS AVELLANEDA
- N°303 SEBASTIAN MUÑOZ
- EDU.N°25 J.J.DE URQUIZA
- N°85 ALVAREZ CONDARCO
- N°310 GOB.R.RODRÍGUEZ SAÁ
- HOGAR N°20 POL.PUNTANA
- EX ESCUELA N° 336 MINISTRO DIÓGENES TABOADA
- N°127 SAN LORENZO
- HOGAR N°4 MTRO.J.M.TISSERA
- EDU.N°7 GEOL.R.GUIÑAZÚ
- N°302 MTRO.CELESTINO JOFRE
- N°306 GOB.ZOILO CONCHA
- N°191 PROV.DE LA PAMPA
- N°24 L.F DE CORTES APARICIO
- N°448 P.A.DE SARMIENTO
- N°422 PROF.E.F.DE GOMEZ
- N°440 SARMIENTO
- N°149 M.LAINEZ
- N°188 PROV.DE SANTA CRUZ
- N°438 B.RIVADAVIA
- N°22 J.M.ESTRADA
- N°243 RIO NEGRO
- HOGAR N°16 GDROS.PUNTANOS
- N°450 NEUQUÉN
- N°45 J.DE DIOS ESCOBAR
- N°454 F.A.ARGENTINA
- ESCUELA PÚBLICA DIGITAL N° 14 LA MAROMA

Ángeles Watters: “Se puede vivir siendo influencer pero a diferencia de lo que muchos creen no es solo posar”

Arturo Costa: “El concepto que usamos mucho con la banda a la hora de tocar y de transmitir algo es eso, la amistad, la unión y hacer lo que nos gusta y divertirnos”

Especial Halloween: 10 pelis de terror y algo más…
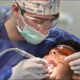
La endodoncia en mi día a día
Ángeles Watters: “Se puede vivir siendo influencer pero a diferencia de lo que muchos creen no es solo posar”
Arturo Costa: “El concepto que usamos mucho con la banda a la hora de tocar y de transmitir algo es eso, la amistad, la unión y hacer lo que nos gusta y divertirnos”
Especial Halloween: 10 pelis de terror y algo más…
La endodoncia en mi día a día
")




_Mesa de trabajo 1")
")

-

 Provincial21 horas ago
Provincial21 horas agoAnticipan un martes nublado y con temperaturas frescas
-

 Provincial21 horas ago
Provincial21 horas agoLa Provincia aumentó a $20 millones la recompensa para quien aporte datos del paradero de Guadalupe
-

 Deportes21 horas ago
Deportes21 horas agoLa Selección argentina se enfrenta con Argelia, en el que será su tan ansiado debut en el Mundial 2026